Multi-hazard risk assessment#
In this notebook, we will perform a multi-hazard risk assessmente for education infrastructure data within a country. The assessment is based on combining hazard data (e.g., flood depths) with OpenStreetMap feature data.
We will follow the steps outlined below to conduct the assessment:
Loading the necessary packages:
We will import the Python libraries required for data handling, analysis, and visualization.Loading the data:
The infrastructure data (e.g., hospitals) and hazard data (e.g., flood depths) will be loaded into the notebook.Preparing the data:
The infrastructure and hazard data will be processed and data gaps can be filled, if required.Performing the risk assessment:
We will overlay the hazard data with the feature information.Visualizing the results:
Finally, we will visualize the estimated exposure using graphs and maps.
1. Loading the Necessary Packages#
To perform the assessment, we are going to make use of several python packages.
In case you run this in Google Colab, you will need to install the packages below (remove the hashtag in front of them). The installation is split into two steps:
Step 1: Install damagescanner first. Because this upgrades NumPy to a newer version than what Colab has pre-installed, Google Colab will prompt you to restart the runtime after installation — accept the restart. This is necessary to ensure the newly installed NumPy version is actually loaded into memory.
Step 2: After the restart, run the second cell to install contextily. This package is installed separately to avoid the installation to fail due to the requested runtime restart.
#!pip install damagescanner
#!pip install contextily
In this step, we will import all the required Python libraries for data manipulation, spatial analysis, and visualization.
import warnings
import xarray as xr
import numpy as np
import pandas as pd
import geopandas as gpd
import seaborn as sns
import shapely
from tqdm import tqdm
import matplotlib.pyplot as plt
import contextily as cx
import damagescanner.download as download
from damagescanner.core import DamageScanner
from damagescanner.osm import read_osm_data
from damagescanner.config import DICT_CIS_VULNERABILITY_FLOOD
from statistics import mode
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=RuntimeWarning) # exactextract gives a warning that is invalid
Specify the country of interest#
Before we continue, we should specify the country for which we want to assess the damage. We use the ISO3 code for the country to download the OpenStreetMap data.
country_full_name = 'Haiti'
country_iso3 = 'HTI'
Specify the hazards of interest#
To help us performing a consistent analysis on which hazards we include, its most convenient to provide a list of the hazards at the start of our analysis.
hazards = ['Earthquake','Flood','Tropical_Cyclone']
2. Loading the Data#
In this step, we will prepare and load two key datasets:
Infrastructure data:
This dataset contains information on the location and type of infrastructure (e.g., roads). Each asset may have attributes such as type, length, and replacement cost.Hazard data:
This dataset includes information on the hazard affecting the infrastructure (e.g., flood depth at various locations).
Infrastructure Data#
We will perform this example analysis for Jamaica. To start the analysis, we first download the OpenStreetMap data from GeoFabrik.
infrastructure_path = download.get_country_geofabrik(country_iso3)
Now we load the data and read only the education data.
%%time
features = read_osm_data(infrastructure_path,asset_type='education')
CPU times: total: 42.7 s
Wall time: 1min 15s
sub_types = features.object_type.unique()
sub_types
<ArrowStringArray>
['school', 'college', 'university', 'kindergarten', 'library']
Length: 5, dtype: str
Vulnerability data#
We will collect all the vulnerability curves for each of the asset types and for each of the hazards. Important to note is that national or local-scale analysis requires a thorough check which curves can and should be used!
vulnerability_path = "https://zenodo.org/records/13889558/files/Table_D2_Hazard_Fragility_and_Vulnerability_Curves_V1.1.0.xlsx?download=1"
collect_vulnerability_dataframes = {}
for hazard in hazards:
if hazard == 'Earthquake':
collect_vulnerability_dataframes[hazard] = pd.read_excel(vulnerability_path,sheet_name='E_Vuln_PGA ')
elif hazard == 'Flood':
collect_vulnerability_dataframes[hazard] = pd.read_excel(vulnerability_path,sheet_name='F_Vuln_Depth')
elif hazard == 'Tropical_Cyclone':
collect_vulnerability_dataframes[hazard] = pd.read_excel(vulnerability_path,sheet_name='W_Vuln_V10m')
And now select a curve to use for each different subtype we are analysing for each of the hazards
selected_curves_dict = {}
selected_curves_dict['Earthquake'] = dict(zip(sub_types,['E21.11','E21.11','E21.11','E21.11','E21.11']))
selected_curves_dict['Flood'] = dict(zip(sub_types,['F21.11','F21.10','F21.10','F21.10','F21.10']))
selected_curves_dict['Tropical_Cyclone'] = dict(zip(sub_types,['W21.2','W21.3','W21.4','W21.5','W21.10']))
We need to ensure that we correctly name the index of our damage_curves pd.DataFrame, and that we convert the index values to the same unit as the hazard data.
hazard_intensity_metric = {'Earthquake': 'PGA',
'Flood' : 'Depth',
'Tropical_Cyclone' : 'WindSpeed'}
aligning_curve_and_hazard_data = {'Earthquake': 980,
'Flood' : 100,
'Tropical_Cyclone' : 1}
And then we can populate a dict() with the damage curves for each hazard included in our analysis.
damage_curves_all_hazards = {}
for hazard in hazards:
vul_df = collect_vulnerability_dataframes[hazard]
damage_curves = vul_df[['ID number']+list(selected_curves_dict[hazard].values())]
damage_curves = damage_curves.iloc[4:125,:]
damage_curves.set_index('ID number',inplace=True)
damage_curves.index = damage_curves.index.rename(hazard_intensity_metric[hazard])
damage_curves = damage_curves.astype(np.float32)
damage_curves.columns = sub_types
damage_curves = damage_curves.ffill()
damage_curves.index = damage_curves.index*aligning_curve_and_hazard_data[hazard]
damage_curves_all_hazards[hazard] = damage_curves
Maximum damages#
One of the most difficult parts of the assessment is to define the maximum reconstruction cost of particular assets. Here we provide a baseline set of values, but these should be updated through national consultations.
Locations of education facilities are (somewhat randomly) geotagged as either points or polygons. This matters quite a lot for the maximum damages. For polygons, we would use damage per square meter, whereas for points, we would estimate the damage to the entire asset at once. Here we take the approach of converting the points to polygons, and there define our maximum damages in dollar per square meter.
maxdam_dict = {'community_centre' : 1000,
'school' : 1000,
'kindergarten' : 1000,
'university' : 1000,
'college' : 1000,
'library' : 1000
}
maxdam = pd.DataFrame.from_dict(maxdam_dict,orient='index').reset_index()
maxdam.columns = ['object_type','damage']
And check if any of the objects are missing from the dataframe.
missing = set(sub_types) - set(maxdam.object_type)
if len(missing) > 0:
print(f"Missing object types in maxdam: \033[1m{', '.join(missing)}\033[0m. Please add them before you continue.")
Ancilliary data for processing#
world = gpd.read_file("https://github.com/nvkelso/natural-earth-vector/raw/master/10m_cultural/ne_10m_admin_0_countries.shp")
world_plot = world.to_crs(3857)
admin1 = gpd.read_file("https://github.com/nvkelso/natural-earth-vector/raw/master/10m_cultural/ne_10m_admin_1_states_provinces.shp")
3. Preparing the Data#
Clip the hazard data to the country of interest.
country_bounds = world.loc[world.ADM0_ISO == country_iso3].bounds
country_geom = world.loc[world.ADM0_ISO == country_iso3].geometry
country_box = shapely.box(country_bounds.minx.values,country_bounds.miny.values,country_bounds.maxx.values,country_bounds.maxy.values)[0]
Hazard Data#
For this example, we make use of the flood, earthquake and tropical cyclone data provided by CDRI.
For our risk assessment, we will need to define a set of return periods for each of the hazards, and create a hazard_dict for each of the hazards well.
hazard_return_periods = {'Earthquake': [250,475,975,1500,2475],
'Flood' : [2,5,10,50,100,200,500,1000],
'Tropical_Cyclone' : [25,50,100,250]
}
And now we can download the hazard data and directly clip this to our country of interest.
hazard_dict_per_hazard = {}
for hazard in hazards:
hazard_dict = {}
for return_period in hazard_return_periods[hazard]:
if hazard == 'Earthquake':
hazard_map = xr.open_dataset(f"https://hazards-data.unepgrid.ch/PGA_{return_period}y.tif", engine="rasterio")
elif hazard == 'Flood':
hazard_map = xr.open_dataset(f"https://hazards-data.unepgrid.ch/global_pc_h{return_period}glob.tif", engine="rasterio")
elif hazard == 'Tropical_Cyclone':
hazard_map = xr.open_dataset(f"https://hazards-data.unepgrid.ch/Wind_T{return_period}.tif", engine="rasterio")
hazard_dict[return_period] = hazard_map.rio.clip_box(minx=country_bounds.minx.values[0],
miny=country_bounds.miny.values[0],
maxx=country_bounds.maxx.values[0],
maxy=country_bounds.maxy.values[0]
)
hazard_dict_per_hazard[hazard] = hazard_dict
Convert point data to polygons.#
For some data, there are both points and polygons available. It makes life easier to estimate the damage using polygons. Therefore, we convert those points to Polygons below.
Let’s first get an overview of the different geometry types for all the assets we are considering in this analysis:
features['geom_type'] = features.geom_type
features.groupby(['object_type','geom_type']).count()['geometry']
object_type geom_type
college MultiPolygon 93
Point 189
kindergarten MultiPolygon 31
Point 253
library MultiPolygon 18
Point 66
school MultiPolygon 1586
Point 4457
university MultiPolygon 76
Point 73
Name: geometry, dtype: int64
The results above indicate that several asset types that are expected to be Polygons are stored as Points as well. It would be preferably to convert them all to polygons. For the Points, we will have to estimate a the average size, so we can use that to create a buffer around the assets.
To do so, let’s grab the polygon data and estimate their size. We grab the median so we are not too much influenced by extreme outliers. If preferred, please change .median() to .mean() (or any other metric).
polygon_features = features.loc[features.geometry.geom_type.isin(['Polygon','MultiPolygon'])].to_crs(3857)
polygon_features['square_m2'] = polygon_features.area
square_m2_object_type = polygon_features[['object_type','square_m2']].groupby('object_type').median()
square_m2_object_type
| square_m2 | |
|---|---|
| object_type | |
| college | 4587.485898 |
| kindergarten | 379.732851 |
| library | 276.183421 |
| school | 3440.494898 |
| university | 15696.049646 |
Now we create a list in which we define the assets we want to “polygonize”:
points_to_polygonize = ['college','kindergarten','library','school','university']
And take them from our data again:
all_assets_to_polygonize = features.loc[(features.object_type.isin(points_to_polygonize)) & (features.geometry.geom_type == 'Point')]
When performing a buffer, it is always best to do this in meters. As such, we will briefly convert the point data into a crs system in meters.
all_assets_to_polygonize = all_assets_to_polygonize.to_crs(3857)
def polygonize_point_per_asset(asset):
# we first need to set a buffer length. This is half of width/length of an asset.
buffer_length = np.sqrt(square_m2_object_type.loc[asset.object_type].values[0])/2
# then we can buffer the asset
return asset.geometry.buffer(buffer_length,cap_style='square')
collect_new_point_geometries = all_assets_to_polygonize.apply(lambda asset: polygonize_point_per_asset(asset),axis=1).set_crs(3857).to_crs(4326).values
features.loc[(features.object_type.isin(points_to_polygonize)) & (features.geometry.geom_type == 'Point'),'geometry'] = collect_new_point_geometries
And check if any “undesired” Points are still left:
features.loc[(features.object_type.isin(points_to_polygonize)) & (features.geometry.geom_type == 'Point')]
| osm_id | geometry | object_type | building | name | geom_type |
|---|
And remove the ‘geom_type’ column again, as we do not need it again.
features = features.drop(['geom_type'],axis=1)
4. Performing the Risk Assessment#
We will use the DamageScanner approach. This is a fully optimised exposure, vulnerability damage and risk calculation method, that can capture a wide range of inputs to perform such an assessment.
save_asset_risk_results = {}
for hazard in hazards:
save_asset_risk_results[hazard] = DamageScanner(hazard_dict_per_hazard[hazard],
features,
curves=damage_curves_all_hazards[hazard],
maxdam=maxdam
).risk(hazard_dict_per_hazard[hazard]
)
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 5/5 [00:23<00:00, 4.60s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [00:35<00:00, 4.45s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 4/4 [00:15<00:00, 3.76s/it]
combine_results = []
for hazard in hazards:
results = save_asset_risk_results[hazard]
combine_results.append(pd.DataFrame(results.rename(columns={'risk': hazard})[hazard]))
risk_outcomes = features.merge(pd.concat(combine_results,axis=1),right_index=True,left_index=True,how='outer')
5. Save the Results#
For further analysis, we can save the results in their full detail, or save summary estimates per subnational unit
risk_outcomes.to_file(f'Healthcare_Multi_Risk_{'_'.join(hazards)}.gpkg')
admin1_country = admin1.loc[admin1.sov_a3 == country_iso3]
risk_outcomes = risk_outcomes.sjoin(admin1_country[['adm1_code','name','geometry']])
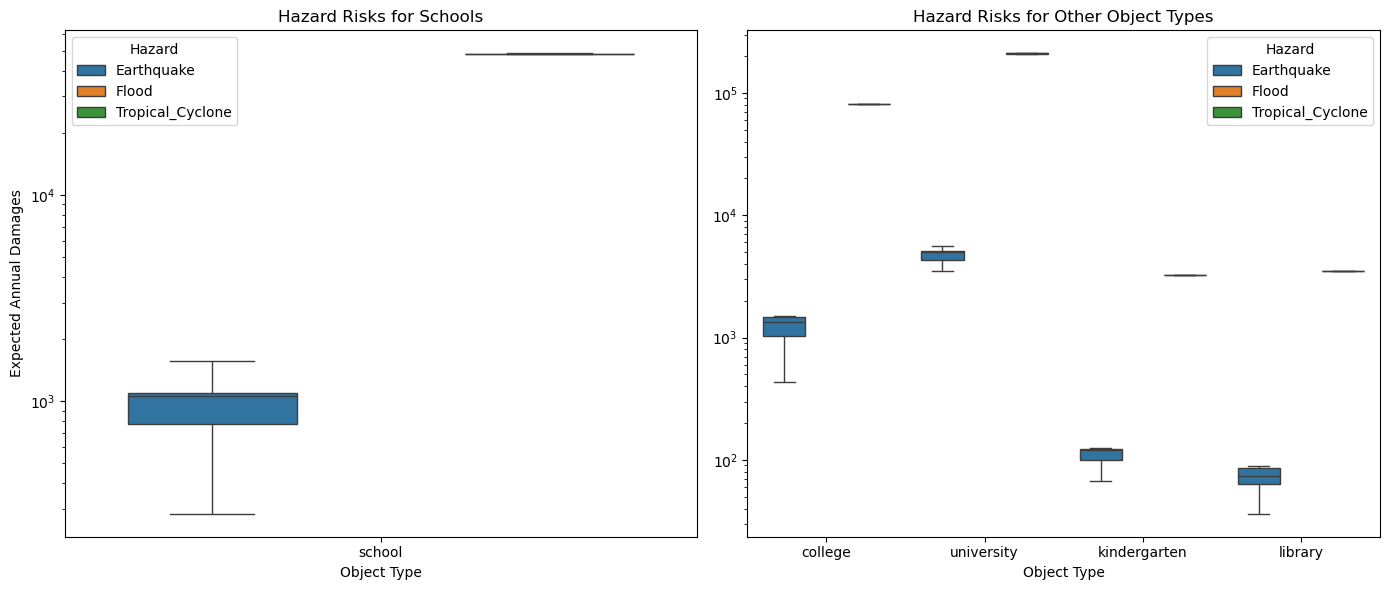
6. Visualising the results#
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# Filter relevant columns
hazard_columns = ['Earthquake', 'Flood', 'Tropical_Cyclone']
# Convert to long format for Seaborn
risk_long = risk_outcomes.melt(id_vars=['object_type'], value_vars=hazard_columns,
var_name='Hazard', value_name='Risk_Level')
# Remove NaN values
risk_long = risk_long.dropna()
# Separate schools from other object types
schools = risk_long[risk_long['object_type'] == 'school']
others = risk_long[risk_long['object_type'] != 'school']
# Set figure size
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Create a boxplot for schools
sns.boxplot(data=schools, x='object_type', y='Risk_Level', hue='Hazard', ax=axes[0],showfliers=False)
axes[0].set_title('Hazard Risks for Schools')
axes[0].set_xlabel('Object Type')
axes[0].set_ylabel('Expected Annual Damages')
axes[0].legend(title='Hazard')
# Create a boxplot for other object types
sns.boxplot(data=others, x='object_type', y='Risk_Level', hue='Hazard', ax=axes[1],showfliers=False)
axes[1].set_title('Hazard Risks for Other Object Types')
axes[1].set_xlabel('Object Type')
axes[1].set_ylabel('')
axes[1].legend(title='Hazard')
# Improve readability
for ax in axes:
ax.set_yscale('log') # Use log scale for better visualization if values vary widely
# Show plot
plt.tight_layout()