Extreme Heat exposure assessment#
In this notebook, we will perform an extreme heat exposure assessment for transportation infrastructure, specifically focusing on railways. The assessment is based on combining hazard data (e.g., occurence of extreme temperatures) with spatial information on railway infrastructure to understand how future climate could increase the impact of extreme heat on the performance of railway infrastructure.
We will follow the steps outlined below to conduct the assessment:
Loading the necessary packages:
We will import the Python libraries required for data handling, analysis, and visualization.Loading the data:
The infrastructure data (e.g., railways) and hazard data (e.g., PGA levels) will be loaded into the notebook.Preparing the data:
The infrastructure and hazard data will be processed and data gaps can be filled, if required.Performing the exposure assessment:
We will overlay the railway infrastructure data with data on extreme heat.Visualizing the results:
Finally, we will visualize the estimated damage using graphs and maps to illustrate the impact on railway infrastructure.
1. Loading the Necessary Packages#
To perform the assessment, we are going to make use of several python packages.
In case you run this in Google Colab, you will need to install the packages below (remove the hashtag in front of them). The installation is split into two steps:
Step 1: Install damagescanner first. Because this upgrades NumPy to a newer version than what Colab has pre-installed, Google Colab will prompt you to restart the runtime after installation — accept the restart. This is necessary to ensure the newly installed NumPy version is actually loaded into memory.
Step 2: After the restart, run the second cell to install contextily. This package is installed separately to avoid the installation to fail due to the requested runtime restart.
#!pip install damagescanner
#!pip install contextily
In this step, we will import all the required Python libraries for data manipulation, spatial analysis, and visualization.
import warnings
import xarray as xr
import numpy as np
import pandas as pd
import geopandas as gpd
import seaborn as sns
import shapely
from tqdm import tqdm
from matplotlib.colors import ListedColormap
from matplotlib.patches import Patch
import matplotlib.pyplot as plt
import contextily as cx
import damagescanner.download as download
from damagescanner.core import DamageScanner
from damagescanner.osm import read_osm_data
from damagescanner.config import DICT_CIS_VULNERABILITY_FLOOD
from statistics import mode
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=RuntimeWarning) # exactextract gives a warning that is invalid
Specify the country of interest#
Before we continue, we should specify the country for which we want to assess the damage. We use the ISO3 code for the country to download the OpenStreetMap data.
country_full_name = 'Serbia'
country_iso3 = 'SRB'
2. Loading the Data#
In this step, we will load four key datasets:
Infrastructure data:
This dataset contains information on the location and type of transportation infrastructure (e.g., roads). Each asset may have attributes such as type, length, and replacement cost.Hazard data:
This dataset includes information on the hazard affecting the infrastructure (e.g., flood depth at various locations).
Infrastructure Data#
To start the analysis, we first download the OpenStreetMap data from GeoFabrik. In case of locally available data, one can load the shapefiles through gpd.read_file().
infrastructure_path = download.get_country_geofabrik(country_iso3)
Now we load the data and read only the road data.
%%time
features = read_osm_data(infrastructure_path,asset_type='rail')
CPU times: total: 27 s
Wall time: 57.8 s
sub_types = features.object_type.unique()
Hazard Data#
Dealing with extreme heat is generally quite complicated. As extreme temperatures vary greatly across the world, infrastructure is also built differently for that wide range of possible temperatures. Moreover, when it comes to extreme heat, we are most interested on how climate change may change those temperature extremes. However, high-resolution climate data is very data-intensive, and it can be complicated to decide which climate model one should use for the specific region of interest. The latest set of climate projections, clustered within [CMIP-6], contains a large amount of different climate runs and climate models. All combined, they show a large possible range of futures.
As such, we strongly suggest to look for regional or nationally-downscaled heat information to perform such an analysis. For the sake of showcasing how one could potentially assess the exposure of extreme heat on infrastructure, we show an example approach using high resolution climate change observations and projections for the evaluation of heat-related extremes developed by **Williams et al., 2024. The full dataset can be found here.
Please note: we require quite a lot of data-specific steps to get this analysis working. As such, different to the other hazards, this approach might be more difficult to quickly re-do with other extreme heat data.
Here we will show how to extract all data to identify how often temperature exceeded 30 degrees, and how this may change towards the future. We will exemplify this approach for Serbia and, as such, only grab the warmest months for Serbia (July and August). For different countries, one may want to select different months. Here we only select two months, as the computational time of the exposure analysis will increase substantially with each additional month added.
Let’s first first select the years and months we want to consider:
years = [str(x) for x in np.arange(1983,2017,1)]
months = ['0'+str(x) for x in np.arange(7,9,1)]
And specify whether we want to look at 30 degrees (30C) or 40.6 (40p6) degrees plus:
Tmax_type = '30C'
Now we first collect the data for the historic time period. We directly clip this data to our region of interest, through taking the bounds of our features data.
collect_country_data = {}
for month in months:
for year in tqdm(years,total=len(years),desc=month):
file_name = f'https://data.chc.ucsb.edu/products/CHC_CMIP6/extremes/Tmax/observations/{month}/Daily_Tmax_{year}_{month}_cnt_Tmaxgt{Tmax_type}.tif'
hazard_map = xr.open_dataset(file_name, engine="rasterio")
collect_country_data[(month,year)]= hazard_map.rio.clip_box(minx=features.total_bounds[0],
miny=features.total_bounds[1],
maxx=features.total_bounds[2],
maxy=features.total_bounds[3]
)
07: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [00:24<00:00, 1.41it/s]
08: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [00:22<00:00, 1.51it/s]
And now we grab the data under SSP5-8.5 for 2050. One could also decide to use a different SSP scenario (SSP2-4.5) or a different year (2030). We just pick the most extreme in this example, so we can show how an extreme future climate can aggrevate the exposure. Again, we directly clip this data to our region of interest, through taking the bounds of our features data.
collect_country_data_2050_SSP585 = {}
for month in months:
for year in tqdm(years,total=len(years),desc=month):
file_name = f'https://data.chc.ucsb.edu/products/CHC_CMIP6/extremes/Tmax/2050_SSP585/{month}/Daily_Tmax_{year}_{month}_cnt_Tmaxgt{Tmax_type}.tif'
hazard_map = xr.open_dataset(file_name, engine="rasterio")
collect_country_data_2050_SSP585[(month,year)]= hazard_map.rio.clip_box(minx=features.total_bounds[0],
miny=features.total_bounds[1],
maxx=features.total_bounds[2],
maxy=features.total_bounds[3]
)
07: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [00:24<00:00, 1.37it/s]
08: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [00:24<00:00, 1.41it/s]
Ancilliary data for processing#
world = gpd.read_file("https://github.com/nvkelso/natural-earth-vector/raw/master/10m_cultural/ne_10m_admin_0_countries.shp")
world_plot = world.to_crs(3857)
admin1 = gpd.read_file("https://github.com/nvkelso/natural-earth-vector/raw/master/10m_cultural/ne_10m_admin_1_states_provinces.shp")
3. Exposure analysis#
Given the complexity of defining the damage of objects to extreme heat, we focus on performing an exposure analysis within this example.
We will first run the exposure analysis for the historical observation, followed by the future climate. This exposure assessment can take quite some time, as we have to overlay exposure hazard information for each year (34 times) for each month.
collect_exposure_historic = []
for month in months:
for year in tqdm(years,total=len(years),desc=month):
country_hazard_data = collect_country_data[(month,year)]
exposed_features = DamageScanner(country_hazard_data, features, pd.DataFrame(), pd.DataFrame()).exposure(return_full=False,disable_progress=True)#'values']
exposed_features['max_exposure'] = exposed_features.apply(
lambda feature: np.max([x for x in feature['values']]), axis=1
)
exposed_features = exposed_features.rename(columns={'max_exposure': (month,year)})
collect_exposure_historic.append(exposed_features[(month,year)])
07: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [03:17<00:00, 5.81s/it]
08: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [03:05<00:00, 5.46s/it]
df_baseline = pd.concat(collect_exposure_historic, axis=1).T.groupby(level=1).sum().T
And the future exposure analysis.
collect_exposure_2050_SSP585 = []
for month in months:
for year in tqdm(years,total=len(years),desc=month):
country_hazard_data = collect_country_data_2050_SSP585[(month,year)]
exposed_features = DamageScanner(country_hazard_data, features, pd.DataFrame(), pd.DataFrame()).exposure(disable_progress=True,return_full=False)#'values']
exposed_features['max_exposure'] = exposed_features.apply(
lambda feature: np.max([x for x in feature['values']]), axis=1
)
exposed_features = exposed_features.rename(columns={'max_exposure': (month,year)})
collect_exposure_2050_SSP585.append(exposed_features[(month,year)])
07: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [03:09<00:00, 5.57s/it]
08: 100%|██████████████████████████████████████████████████████████████████████████████| 34/34 [03:15<00:00, 5.75s/it]
df_future = pd.concat(collect_exposure_2050_SSP585,axis=1).T.groupby(level=1).sum().T
4. Save the Results#
For further analysis, we can save the results in their full detail, or save summary estimates per subnational unit. We show how to do this using the damage results.
features.merge(df_baseline,left_index=True,right_index=True).to_file(f'Railways_historic_heat_exposure_{country_full_name}.gpkg')
features.merge(df_future,left_index=True,right_index=True).to_file(f'Railways_SSP585_2050_heat_exposure_{country_full_name}.gpkg')
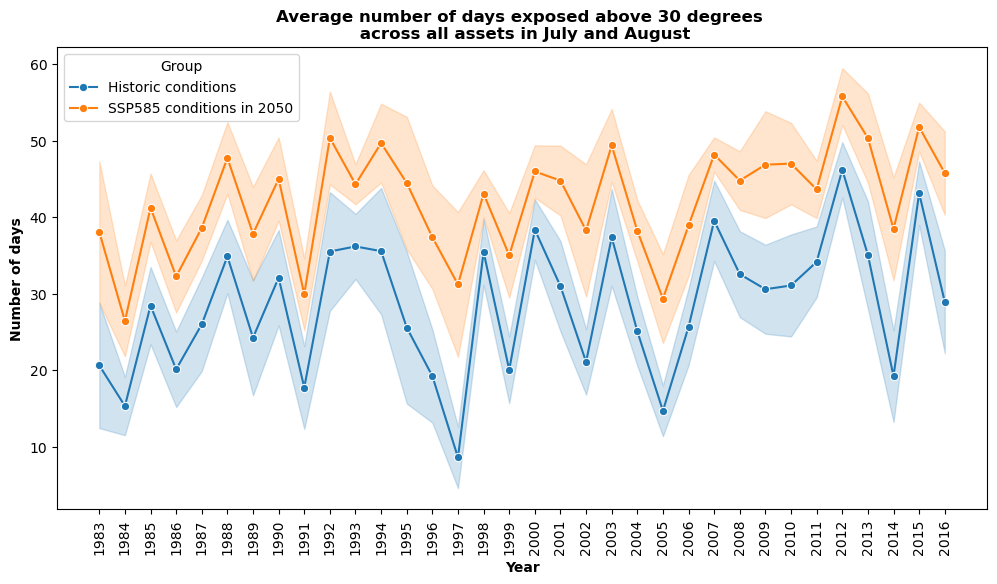
5. Visualizing the Results#
The results of the exposure assessment can be visualized using charts and maps.
Please not that future climate conditions are forced on the historical timeseries. As such, while they both show results from 1983 to 2017, the SSP5-8.5 results show how those historic conditions would worsen under future climate conditions in 2050.
# Convert df_baseline to long format and add a group identifier
df_baseline_long = df_baseline.melt(var_name='Year', value_name='Value')
df_baseline_long['Year'] = df_baseline_long['Year'].astype(int)
df_baseline_long['Group'] = 'Historic conditions'
# Convert df_future to long format and add a group identifier
df_future_long = df_future.melt(var_name='Year', value_name='Value')
df_future_long['Year'] = df_future_long['Year'].astype(int)
df_future_long['Group'] = 'SSP585 conditions in 2050'
# Concatenate the two long dataframes
df_combined = pd.concat([df_baseline_long, df_future_long], axis=0)
# Define a color palette for the two groups
palette = {
'Historic conditions': '#1f77b4', # blue-ish
'SSP585 conditions in 2050': '#ff7f0e' # orange-ish
}
plt.figure(figsize=(12, 6))
sns.lineplot(x='Year', y='Value', hue='Group', data=df_combined, ci='sd', marker='o', palette=palette)
plt.title('Average number of days exposed above 30 degrees \n across all assets in July and August', fontweight='bold')
plt.xlabel('Year', fontweight='bold')
plt.ylabel('Number of days', fontweight='bold')
# Ensure the x-axis shows all years and rotates labels 90 degrees
min_year = df_combined['Year'].min()
max_year = df_combined['Year'].max()
all_years = range(min_year, max_year + 1)
plt.xticks(all_years, rotation=90)
plt.show()
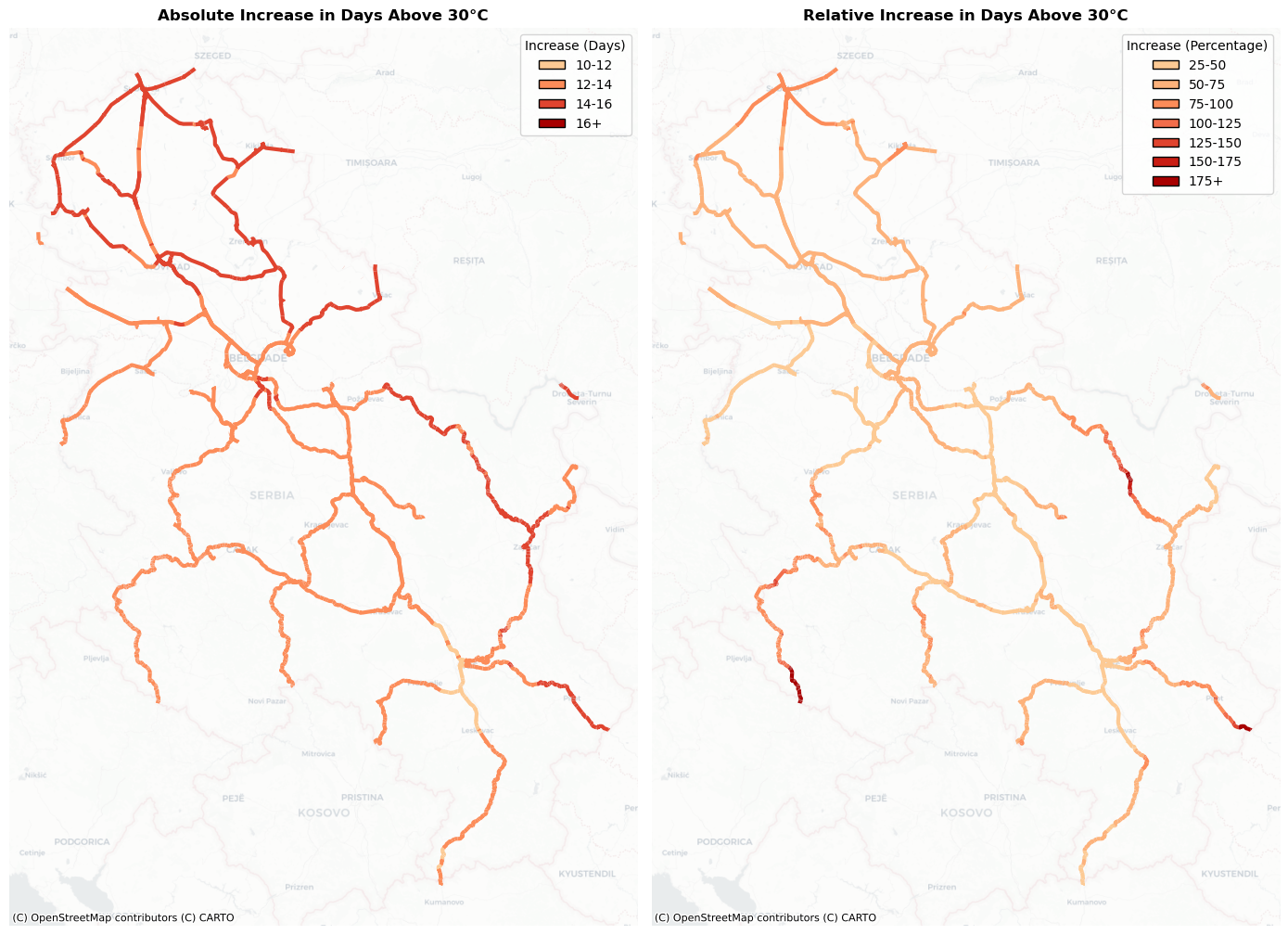
Spatial visualisation#
To gain a better understanding how extreme heat affects the assets, we will create a multi-plot, in which we visualise the absolute and relative increase in days above 30 degrees.
relative_increase = ((df_future-df_baseline)/df_baseline)*100
relative_increase = pd.DataFrame(relative_increase.mean(axis=1)).rename(columns = {0:'mean_increase'})
all_features_exposed = features.merge(relative_increase,left_index=True,right_index=True)
all_features_exposed['abs_increase'] = (df_future-df_baseline).mean(axis=1).values
# Ensure that all_features_exposed is in EPSG:3857 for proper basemap overlay
if all_features_exposed.crs.to_string() != 'EPSG:3857':
all_features_exposed = all_features_exposed.to_crs(epsg=3857)
# ---------------------------------
# Left Panel: Binned Absolute Increase
# ---------------------------------
# Define bins for absolute increase between 10 and 16.
# Values between 10-12, 12-14, 14-16, and above 16.
abs_bins = [10, 12, 14, 16, np.inf]
abs_labels = ['10-12', '12-14', '14-16', '16+']
all_features_exposed['abs_inc_cat'] = pd.cut(
all_features_exposed['abs_increase'],
bins=abs_bins,
labels=abs_labels,
include_lowest=True
)
# Create a discrete colormap for the abs_increase bins using a Blues palette.
n_abs = len(abs_labels)
abs_cmap = ListedColormap(plt.cm.OrRd(np.linspace(0.3, 0.9, n_abs)))
abs_cat_to_color = {label: abs_cmap.colors[i] for i, label in enumerate(abs_labels)}
# ---------------------------------
# Right Panel: Classified Mean Increase
# ---------------------------------
# Define classification bins for mean_increase from 25 to 175, with a final bin for >=175.
mean_bins = [25, 50, 75, 100, 125, 150, 175, np.inf]
mean_labels = ['25-50', '50-75', '75-100', '100-125', '125-150', '150-175', '175+']
all_features_exposed['mean_inc_cat'] = pd.cut(
all_features_exposed['mean_increase'],
bins=mean_bins,
labels=mean_labels,
include_lowest=True
)
# Create a discrete colormap for mean_increase using an OrRd palette.
n_mean = len(mean_labels)
mean_cmap = ListedColormap(plt.cm.OrRd(np.linspace(0.3, 0.9, n_mean)))
mean_cat_to_color = {label: mean_cmap.colors[i] for i, label in enumerate(mean_labels)}
# ---------------------------------
# Create the Multiplot Figure
# ---------------------------------
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 10))
# Left Panel: Plot the binned absolute increase
for cat in abs_labels:
subset = all_features_exposed[all_features_exposed['abs_inc_cat'] == cat]
if not subset.empty:
subset.plot(ax=ax1, color=abs_cat_to_color[cat], linewidth=3, label=cat)
cx.add_basemap(ax1, source=cx.providers.CartoDB.Positron, alpha=0.5)
ax1.set_title("Absolute Increase in Days Above 30°C",fontweight='bold')
ax1.set_axis_off()
legend_handles_left = [Patch(facecolor=abs_cat_to_color[cat], edgecolor='black', label=cat) for cat in abs_labels]
ax1.legend(handles=legend_handles_left, title="Increase (Days)", loc='upper right')
# Right Panel: Plot the classified mean increase with thicker lines
for cat in mean_labels:
subset = all_features_exposed[all_features_exposed['mean_inc_cat'] == cat]
if not subset.empty:
subset.plot(ax=ax2, color=mean_cat_to_color[cat], linewidth=3, label=cat)
cx.add_basemap(ax2, source=cx.providers.CartoDB.Positron, alpha=0.5)
ax2.set_title("Relative Increase in Days Above 30°C",fontweight='bold')
ax2.set_axis_off()
legend_handles_right = [Patch(facecolor=mean_cat_to_color[cat], edgecolor='black', label=cat) for cat in mean_labels]
ax2.legend(handles=legend_handles_right, title="Increase (Percentage)", loc='upper right')
plt.tight_layout()
plt.show()