Country-level risk assessment#
In this notebook, we will perform a risk assessmente for all available CI data within a country. The assessment is based on combining hazard data (e.g., flood depths) with OpenStreetMap feature data.
We will follow the steps outlined below to conduct the assessment:
Loading the necessary packages:
We will import the Python libraries required for data handling, analysis, and visualization.Loading the data:
The infrastructure data (e.g., roads) and hazard data (e.g., flood depths) will be loaded into the notebook.Preparing the data:
The infrastructure and hazard data will be processed and data gaps can be filled, if required.Performing the risk assessment:
We will overlay the hazard data with the feature information.Visualizing the results:
Finally, we will visualize the estimated exposure using graphs and maps.
1. Loading the Necessary Packages#
To perform the assessment, we are going to make use of several python packages.
In case you run this in Google Colab, you will need to install the packages below (remove the hashtag in front of them). The installation is split into two steps:
Step 1: Install damagescanner first. Because this upgrades NumPy to a newer version than what Colab has pre-installed, Google Colab will prompt you to restart the runtime after installation — accept the restart. This is necessary to ensure the newly installed NumPy version is actually loaded into memory.
Step 2: After the restart, run the second cell to install contextily. This package is installed separately to avoid the installation to fail due to the requested runtime restart.
#!pip install damagescanner
#!pip install contextily
In this step, we will import all the required Python libraries for data manipulation, spatial analysis, and visualization.
import warnings
import xarray as xr
import numpy as np
import pandas as pd
import geopandas as gpd
import seaborn as sns
import shapely
from tqdm import tqdm
import matplotlib.pyplot as plt
import contextily as cx
import damagescanner.download as download
from damagescanner.core import DamageScanner
from damagescanner.osm import read_osm_data
from damagescanner.config import DICT_CIS_VULNERABILITY_FLOOD
from statistics import mode
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=RuntimeWarning) # exactextract gives a warning that is invalid
Specify the country of interest#
Before we continue, we should specify the country for which we want to assess the damage. We use the ISO3 code for the country to download the OpenStreetMap data.
country_full_name = 'Belize'
country_iso3 = 'BLZ'
2. Loading the Data#
In this step, we will prepare and load two key datasets:
Infrastructure data:
This dataset contains information on the location and type of infrastructure (e.g., roads). Each asset may have attributes such as type, length, and replacement cost.Hazard data:
This dataset includes information on the hazard affecting the infrastructure (e.g., flood depth at various locations).
Infrastructure Data#
We will perform this example analysis for Jamaica. To start the analysis, we first download the OpenStreetMap data from GeoFabrik.
infrastructure_path = download.get_country_geofabrik(country_iso3)
We will not load the data directly, we will let the code itself read the information. It is important, however, to specificy which infrastructure systems you want to include. We do so in the list below:
asset_types = [
"roads",
"rail",
"air",
"telecom",
"water_supply",
"waste_solid",
"waste_water",
"education",
"healthcare",
"power",
"gas",
"oil",
]
Vulnerability data#
We will collect all the vulnerability curves for each of the asset types. Important to note is that national or local-scale analysis requires a thorough check which curves can and should be used!
vulnerability_path = "https://zenodo.org/records/10203846/files/Table_D2_Multi-Hazard_Fragility_and_Vulnerability_Curves_V1.0.0.xlsx?download=1"
vul_df = pd.read_excel(vulnerability_path,sheet_name='F_Vuln_Depth')
damage_curves_all_ci = {}
for ci_type in DICT_CIS_VULNERABILITY_FLOOD:
ci_system = DICT_CIS_VULNERABILITY_FLOOD[ci_type]
selected_curves = []
for subtype in ci_system:
selected_curves.append(ci_system[subtype][0])
damage_curves = vul_df[['ID number']+selected_curves]
damage_curves = damage_curves.iloc[4:125,:]
damage_curves.set_index('ID number',inplace=True)
damage_curves.index = damage_curves.index.rename('Depth')
damage_curves = damage_curves.astype(np.float32)
damage_curves.columns = list(ci_system.keys())
damage_curves = damage_curves.ffill()
# Make sure we set the index of the damage curves (the inundation depth) in the same metric as the hazard data (e.g. meters or centimeters).
damage_curves.index = damage_curves.index*100
damage_curves_all_ci[ci_type] = damage_curves
Maximum damages#
One of the most difficult parts of the assessment is to define the maximum reconstruction cost of particular assets. As such, we sometimes may want to run the analysis without already multiplying the results with those costs. To do so, we simply set all the maximum damage values to 1:
MAXDAM_DICT = {
"roads": {
"motorway" : 2000,
"motorway_link" : 2000,
"trunk" : 2000,
"trunk_link" : 2000,
"primary" : 2000,
"primary_link": 2000,
"secondary" : 1300,
"secondary_link" : 1300,
"tertiary" : 700,
"tertiary_link" : 700,
"residential" : 300,
"road" : 300,
"unclassified" : 300,
"track" : 300,
"service" : 300,
},
"rail": {
'rail' : 2500,
},
"air": {
"aerodrome" : 850,
"terminal" : 1000,
"runway" : 700,},
"telecom": { # curves beschikbaar voor overstromingen
"mast" : 100000, #entire unit
"communications_tower" :100000, #entire unit,
},
"water_supply": {
"water_works" : 1000, # m2,
"water_well": 1000, # m2,
"water_tower": 100000, #entire unit,
"reservoir_covered": 0,
"storage_tank": 25000, #entire unit,
},
"waste_solid": {
"waste_transfer_station" : 1000, # m2,
},
"education": {
"school" : 1100,
"kindergarten" : 1100,
"college": 1100,
"university": 1100,
"library": 1100,
},
"healthcare": { # curves beschikbaar voor overstromingen
"hospital" : 1100,
"clinic" : 1100,
"doctors" : 1100,
"pharmacy" : 1100,
"dentist" :1100,
"physiotherapist" : 1100,
"alternative" : 1100,
"laboratory" : 1100,
"optometrist" : 1100,
"rehabilitation" : 1100,
"blood_donation" : 1100,
"birthing_center" : 1100,
},
"power": {
"line" : 250, #m
"cable" : 250, #m
"minor_line" : 250, #m
"plant" : 5000 , #m2
"generator" : 5000 , #m2
"substation" : 5000 , #m2
"transformer" : 5000 , #m2
"pole" : 100000, #entire unit,
"portal" : 5000 , #m2
"tower" : 100000, #entire unit,
"terminal" : 5000 , #m2
"switch" : 5000 , #m2
"catenary_mast" : 100000, #entire unit,
},
"wastewater": {
"wastewater_plant" : 2500, #m2,
"waste_transfer_station": 1000, #m2,
},
}
maxdam_all_ci = {}
for ci_type in MAXDAM_DICT:
maxdam_dict = MAXDAM_DICT[ci_type]
maxdam = pd.DataFrame.from_dict(maxdam_dict,orient='index').reset_index()
maxdam.columns = ['object_type','damage']
maxdam_all_ci[ci_type] = maxdam
Hazard Data#
For this example, we make use of the flood data provided by CDRI.
We use a 1/100 flood map to showcase the approach.
hazard_map = xr.open_dataset("https://hazards-data.unepgrid.ch/global_pc_h100glob.tif", engine="rasterio")
Ancilliary data for processing#
world = gpd.read_file("https://github.com/nvkelso/natural-earth-vector/raw/master/10m_cultural/ne_10m_admin_0_countries.shp")
world_plot = world.to_crs(3857)
3. Preparing the Data#
Clip the hazard data to the country of interest.
country_bounds = world.loc[world.ADM0_ISO == country_iso3].bounds
country_geom = world.loc[world.ADM0_ISO == country_iso3].geometry
country_box = shapely.box(country_bounds.minx.values,country_bounds.miny.values,country_bounds.maxx.values,country_bounds.maxy.values)[0]
Set the return periods and download the hazard data
return_periods = [2,5,10,50,100,200,500,1000]
hazard_dict = {}
for return_period in return_periods:
hazard_map = xr.open_dataset(f"https://hazards-data.unepgrid.ch/global_pc_h{return_period}glob.tif", engine="rasterio")
hazard_dict[return_period] = hazard_map.rio.clip_box(minx=country_bounds.minx.values[0],
miny=country_bounds.miny.values[0],
maxx=country_bounds.maxx.values[0],
maxy=country_bounds.maxy.values[0]
)
4. Performing the Risk Assessment#
We will use the DamageScanner approach. This is a fully optimised exposure, vulnerability damage and risk calculation method, that can capture a wide range of inputs to perform such an assessment.
save_asset_risk_results = {}
for asset_type in asset_types:
try:
save_asset_risk_results[asset_type] = DamageScanner(hazard_dict[2],
infrastructure_path,
curves=damage_curves_all_ci[asset_type],
maxdam=maxdam_all_ci[asset_type]
).risk(hazard_dict,
asset_type=asset_type
)
except:
print(f"It seems that {asset_type} is most likely not mapped or has no exposure")
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [02:34<00:00, 19.29s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [00:17<00:00, 2.16s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [01:40<00:00, 12.56s/it]
Risk Calculation: 0%| | 0/8 [00:11<?, ?it/s]
It seems that telecom is most likely not mapped or has no exposure
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [01:24<00:00, 10.54s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [01:17<00:00, 9.73s/it]
It seems that waste_water is most likely not mapped or has no exposure
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [01:22<00:00, 10.26s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [01:25<00:00, 10.73s/it]
Risk Calculation: 100%|██████████████████████████████████████████████████████████████████| 8/8 [01:48<00:00, 13.58s/it]
It seems that gas is most likely not mapped or has no exposure
It seems that oil is most likely not mapped or has no exposure
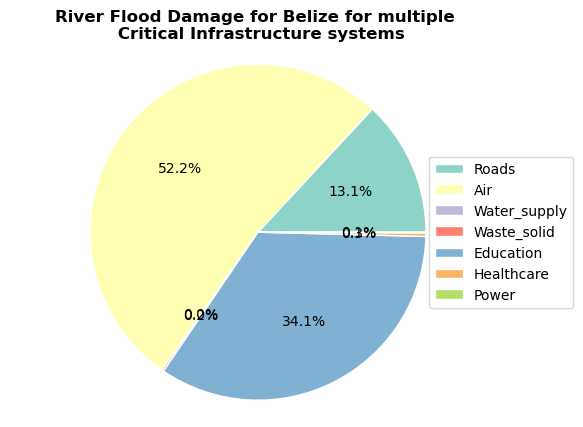
5. Visualising the results#
collect_risk = {}
for asset_type in asset_types:
try:
risk_results = save_asset_risk_results[asset_type]
if (risk_results is None) or len(risk_results) == 0:
continue
else:
collect_risk[asset_type] = risk_results.risk.sum()
except:
continue
colors = ['#8dd3c7','#ffffb3','#bebada','#fb8072','#80b1d3','#fdb462','#b3de69','#fccde5','#d9d9d9']
labels = [x.capitalize() for x in list(collect_risk.keys())]
sizes = collect_risk.values()
pie = plt.pie(sizes,autopct='%1.1f%%', labeldistance=1.15, wedgeprops = { 'linewidth' : 1, 'edgecolor' : 'white' }, colors=colors);
plt.axis('equal')
plt.legend(loc = 'right', labels=labels,bbox_to_anchor=(1.15, 0.5),)
plt.title(f'River Flood Damage for {country_full_name} for multiple \n Critical Infrastructure systems',fontweight='bold')
Text(0.5, 1.0, 'River Flood Damage for Belize for multiple \n Critical Infrastructure systems')